
Mission Confiée
Un corpus documentaire rédigé en Markdown et servi par l'applicatif PHP Daux.io est mis à ma
disposition. Il permet à Springcard de rédiger leur documentations.
Voilà à quoi il ressemble :
Voilà à quoi il ressemble :
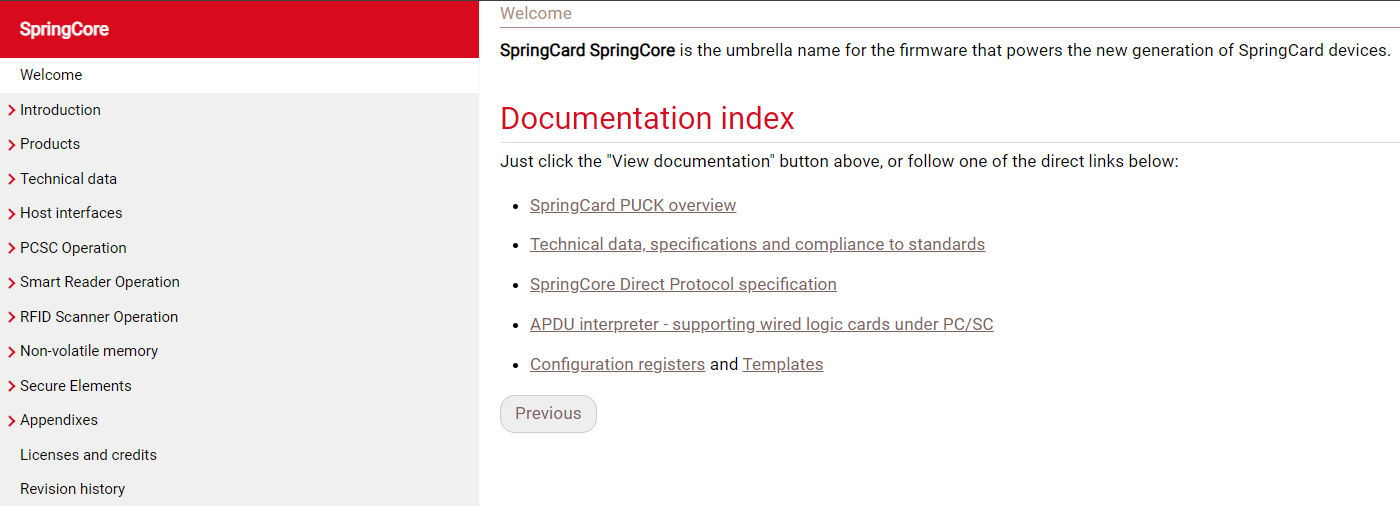
Ma mission était de générer un document PDF à partir de cet ensemble de fichiers Markdown.
il faut assembler un document complet avec
une hiérarchie de chapitres corrects à partir de documents qui
ont leur hiérarchie propre dans une arborescence. (Un H1 dans
un document qui est à la racine (niveau 0) reste un H1, mais un
H1 qui est en profondeur 1 dans l'arborescence devient un H2,
un H1 qui est en profondeur 2 dans l'arborescence devient un
H3, et ainsi de suite.) Il faut donc parcourir les fichiers/dossiers
du corpus puis prendre les informations de celui-ci pour en faire
un seul et même fichier Markdown bien trié et complet.
Je devais ensuite à partir du document complet créer un PDF.
Pour finir un PDF professionnel est attendu avec un en-tête et un pied de page qui correspondent
à une charte graphique.
Tâches effectuées
Mission 1 : Compréhension et analyse
Dans un premier temps il faut vraiment comprendre ce qu’est le Markdown :

Markdown c’est un langage de balisage léger créé en 2004. Il a
été créé dans le but d'offrir une syntaxe facile à lire et à écrire.
C’est donc comme le html mais en plus simple et avec quelques
fonctionnalités en moins.
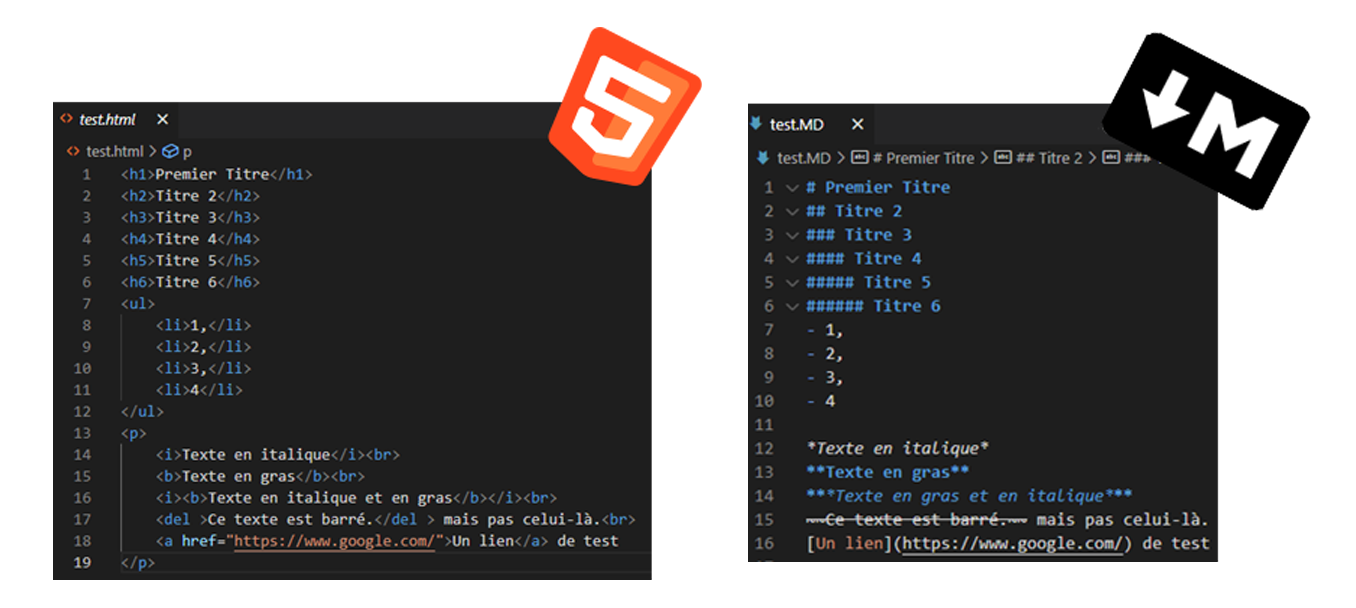
Par exemple un titre en HTML ce sont des balises au début et à
la fin alors qu’en Markdown c’est simplement un ou plusieurs
dièses au début. Pour bien comprendre j’ai réalisé un exemple
en Markdown et un exemple en Html qui devraient avoir le même
rendu :
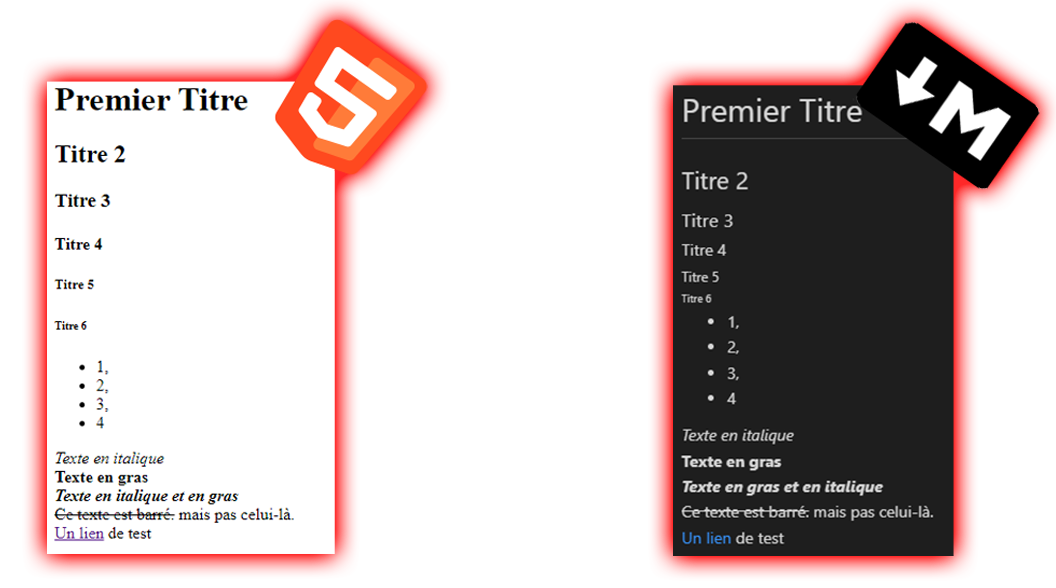
Donne ceci :
Pour ce qui est de l’arborescence à parcourir elle ressemblait à ceci :
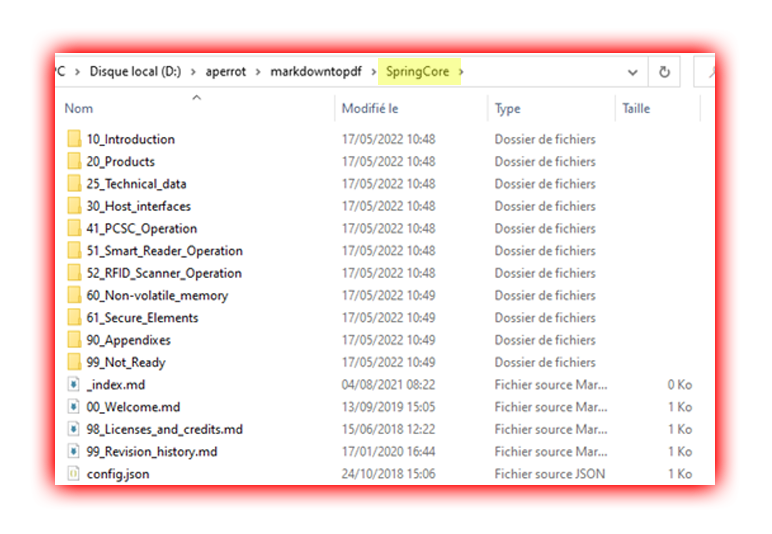
Je vais donc travailler dans le dossier SpringCore qui est la racine.
Mission 2 : Parcourir l’arborescence du corpus
Dans un premier temps j’ai réfléchi à l’algorithme de parcours.
J’ai commencé sur papier à me faire des schémas mais
rapidement, étant donné que je suis plus à l’aise avec le langage
PHP j’ai commencé à développer un programme.

Après plusieurs recherches et des nouvelles notions à apprendre
j’ai finalement réussi à parcourir tous les fichiers.
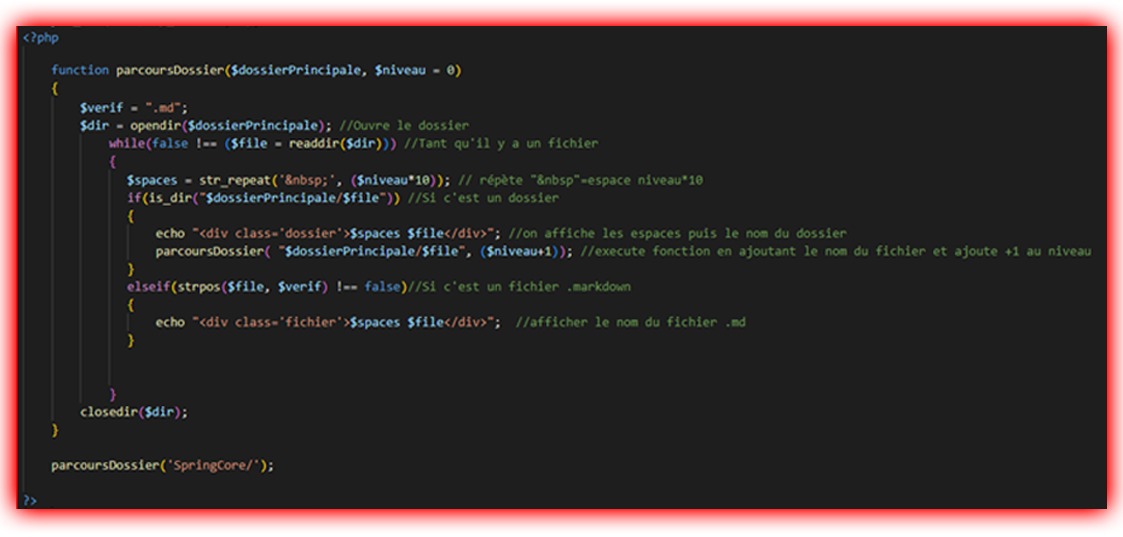
J’affichais donc le nom du dossier/fichier avec un nombre d’espaces devant celui-ci qui correspondait à son niveau dans l’arborescence :

Je voulais ensuite afficher le contenu des fichiers et il m’a suffi d’ajouter ces deux lignes :

J’ouvre dans un premier temps le fichier dans lequel je suis puis j’affiche son contenu avec le nombre d’espaces :

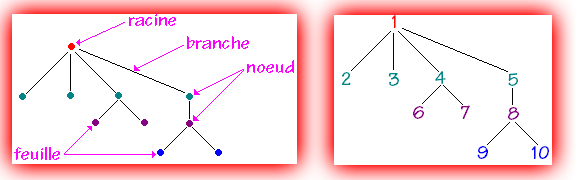
J’avais donc la logique du parcours d’arbre, il faut voir l’arborescence de fichiers comme un arbre à l’envers :
J’avais la logique certes, mais le problème c’est qu’au final je devais sortir un "logiciel".
Le problème c’est que j’utilisais PHP en Web, j’ai donc effectué plusieurs recherches pour
changer de langage et m’orienter vers celui qui me semblait le mieux pour réaliser la mission de A à Z.
En effectuant des recherches j’ai trouvé une bibliothèque du nom de MDPDF sur le site npm.js que Arthur TRON
m’a encouragé à visiter pour utiliser les
différentes bibliothèques qui étaient proposées.

MDPDF pour Markdown to PDF permet de convertir des fichiers Markdown en HTML puis en PDF, elle supporte la prise en charge des en-têtes de page,
des pieds de page, des feuilles de style personnalisées et elle est très configurable. Pour installer cette bibliothèque je devais donc installer NodeJs,
le langage qui me semblait le mieux était donc Javascript sur NodeJs.
J’ai donc installé NodeJs pour pouvoir utiliser la bibliothèque en question.
Une fois installé j’ai essayé d’installer mdpdf mais impossible, une erreur s’affichait :
Une fois installé j’ai essayé d’installer mdpdf mais impossible, une erreur s’affichait :

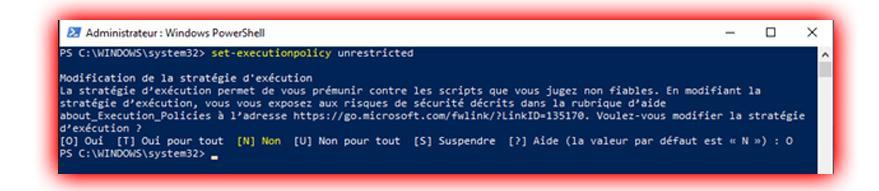
Il suffisait de lancer PowerShell en administrateur pour activer l’exécution de script :

Pour installer une bibliothèque de npm : npm i « le nom de la bibliothèque »
(i pour « install »). J’ai utilisé le terminal de VsCode pour
développer en JavaScript sur NodeJs et installer les différentes bibliothèques.
Une fois la bibliothèque installée, je devais tester si elle fonc-tionnait bien, pour exécuter une commande/un paquet il suffit d’écrire : npx « le nom de la commande » « le nom du fichier » :

Une fois la commande exécutée, une confirmation apparait :

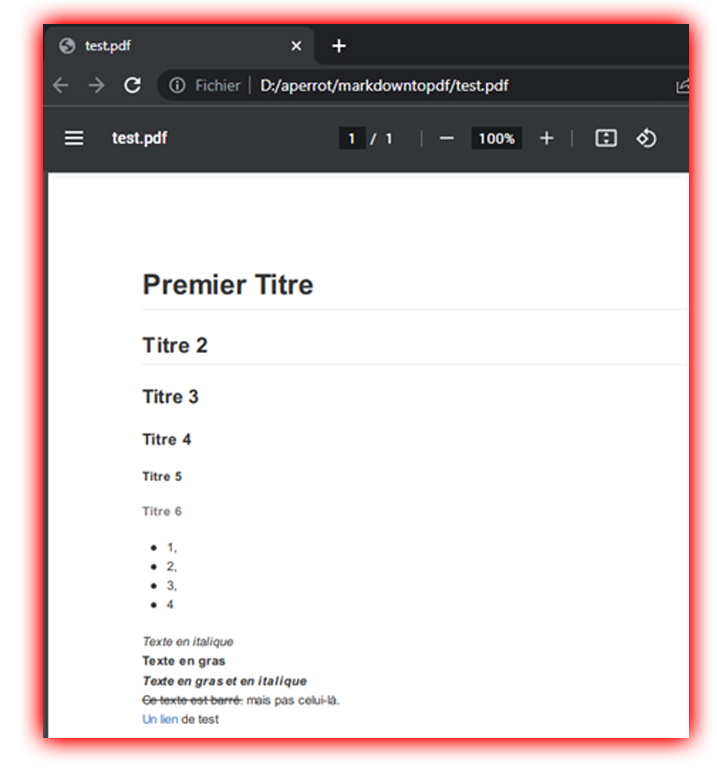
Le PDF était créé et voilà à quoi il ressemblait :
Une fois la certitude que je pouvais faire la dernière étape avec seulement une commande je me suis lancé dans le parcours de fichiers et l’affichage de leur contenu en NodeJs.
Pour lancer un script en NodeJs il faut le préciser dans le fichier package.json.
Ce fichier contient l’objet scripts, il permet de définir des alias permettant l’exécution de commandes :
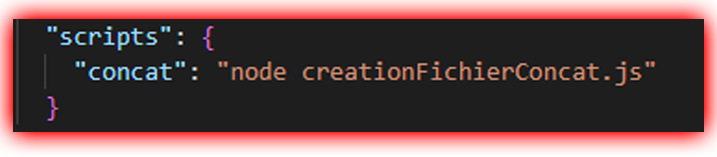
En tapant dans la console npm run concat, le fichier
creationFichierConcat.js s’exécutera ! Il ne me restait donc plus qu’à alimenter creationFichierConcat.js.
Mission 3 : Parcourir l’arborescence du corpus en javascript et afficher son contenu
je devais apprendre à utiliser File System de NodeJs. NodeJs propose une façon intuitive de travailler avec
le système de fichiers à travers son module fs pour “File System”.
Le module est livré nativement avec NodeJs, pour l’inclure il suffit d’utiliser la fonction require :

Pour parcourir une arborescence j’ai recherché si une
bibliothèque existait. La bibliothèque Glob revenait souvent, beaucoup en parlait sur les forums et elle était disponible sur Npm.js.

Glob fonctionne comme la commande LS, elle permet de lister tout le contenu d’un répertoire. Je l’ai donc installée.
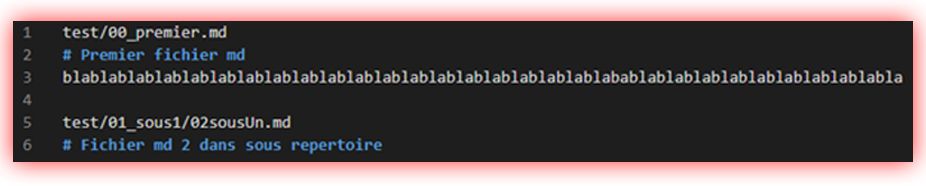
avant de travailler sur l’arborescence plutôt conséquente j’ai commencé à créer un dossier « test » avec
2 fichiers que je ne devais pas afficher et une arborescence semblable au dossier SpringCore mais bien moins vaste :
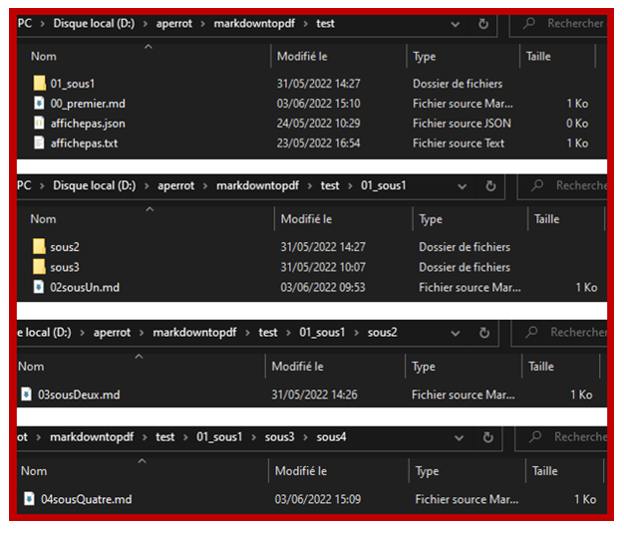
Voilà donc à quoi ressemblait l’arborescence de test que je m’étais préparée. Après avoir compris comment bien utiliser les différentes bibliothèques j’ai eu mon premier rendu :
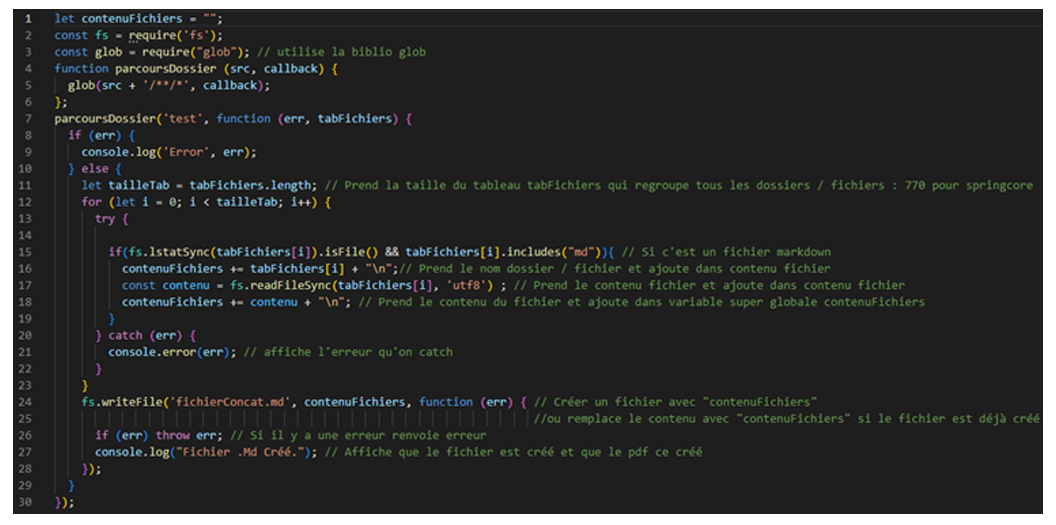
Qui me permettait d’obtenir un fichier « fichierConcat.md » qui regroupe le contenu et le nom des fichiers / dossiers.
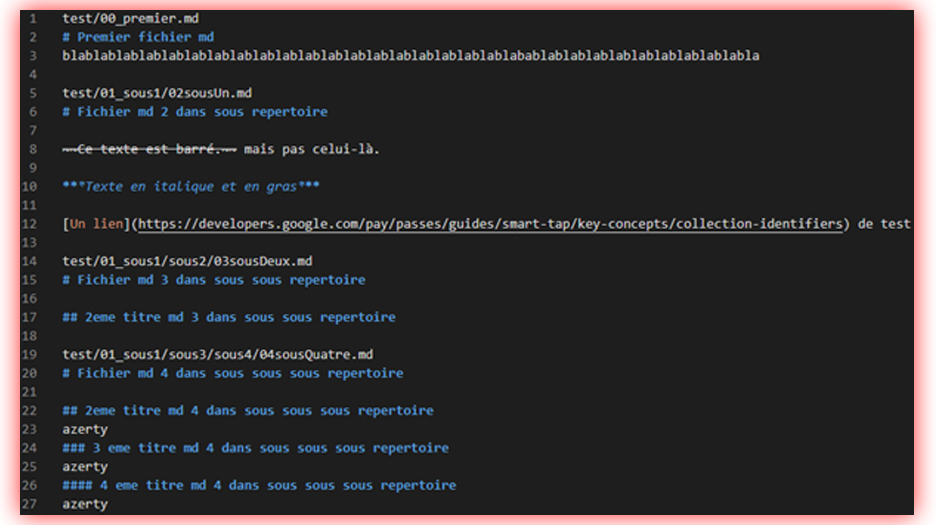
Parfait, les deux fichiers « affichepas » ne s’affichaient pas. J’ai donc essayé de transformer ce fichier en PDF avec MDPDF mais une erreur est apparue :

La création du PDF prenait trop de temps, je me suis donc rendu dans le fichier pdf.js du node_modules comme indiqué sur l’erreur.
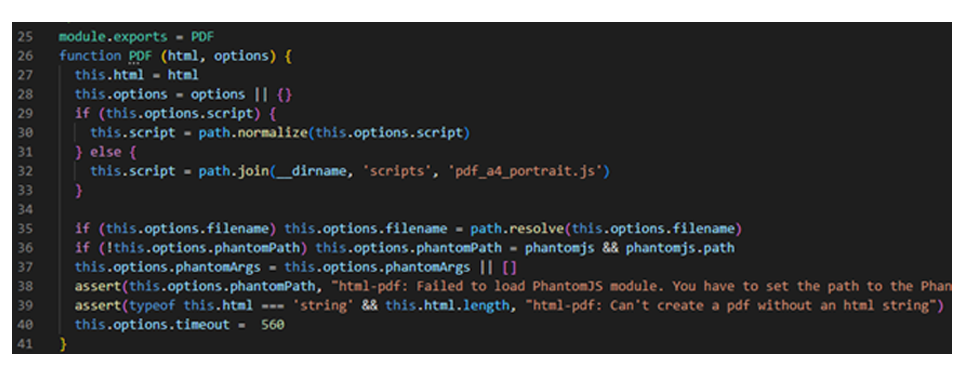
Rapidement j’ai compris que le timeout était trop court. Je l’ai donc modifié avec une grande valeur pour qu’il ne m’empêche plus de travailler :

Une fois le timeout changé je pouvais créer mon fichier pdf, je pouvais donc continuer. J’arrivais à parcourir les fichiers /
dossiers et afficher le contenu dans l’ordre, cependant je ne
prenais pas encore en compte la profondeur et si le dossier à la racine existait bien. Pour ce qui est de la profondeur j’ai eu une idée, un fichier ne peut pas contenir de « / » dans son nom et comme on peut le voir ici :
Les « / » séparent les dossiers. S’il y a deux « / » alors la
profondeur est de 2. J’avais donc plusieurs missions : Vérifier si le dossier à parcourir existe bien, Compter le nombre de « / » pour connaitre la profondeur et donc l’appliquer aux titres et lire ligne par ligne par les fichiers Markdown pour savoir où sont les titres et comment les traiter. Johann Dantant m’a éga-lement
demandé de sortir la profondeur Maximum et également de faire en sorte que les fichiers qui se nomment _index.md dans
l’arborescence soient avec une profondeur de moins.
Mission 4 : Vérifier que le dossier à parcourir existe bien
La vérification est simple, je prends la taille du tableau
« tabFichiers » qui regroupe tous les dossiers / fichiers et s’il est vide alors c’est qu’il n’existe pas ou qu’il est vide :

Mission 5 : Compter le nombre de « / » pour la profondeur
Pour ça j’ai créé une fonction qui permet de compter le nombre de fois qu’un caractère est présent :

Que j’utilise comme ceci :

J’ai donc la profondeur actuelle du fichier / dossier que je traite et je stocke toutes les profondeurs dans « stockProf ».
Mission 6 : Lire ligne par ligne pour identifier les titres et y appliquer la profondeur
C’est sûrement la mission qui m’a posée le plus de problème car je ne connaissais pas la notion de Synchrone :
Ça exécute immédiatement l’intégralité des instructions puis retourne une valeur dans la foulée et le reste du programme attend la fin de
l’exécution de cette fonction avant de s’exécuter à son tour. Ainsi, quand on appelle plusieurs fonctions synchrones d’affilée,
on a la garantie qu’elles s’exécutent de manière séquentielle. L’une après l’autre. Exemple :

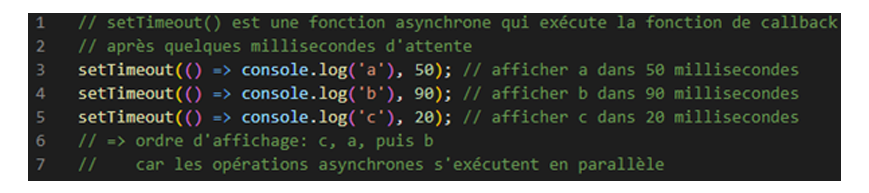
Et d’Asynchrone :
Quand on appelle plusieurs fonctions asynchrones d’affilée, elles ne seront pas forcément exécutées dans le même ordre. Exemple :
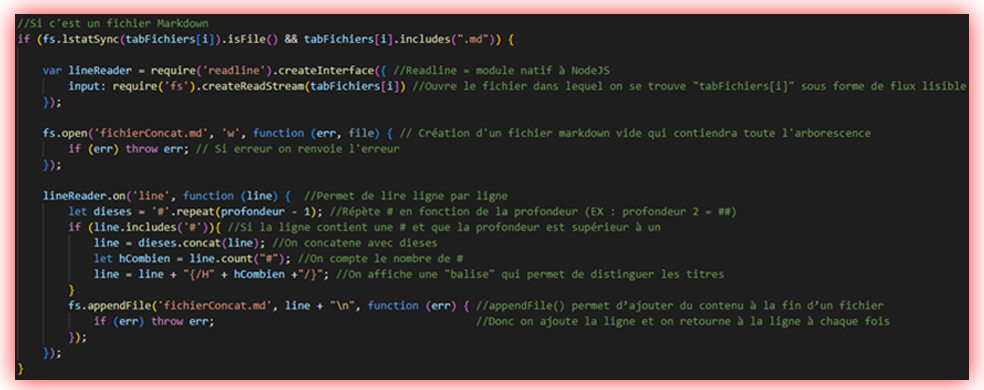
Pour lire ligne par ligne j’ai utilisé le module natif de NodeJs : Readline.
Ensuite pour afficher la profondeur maximum dans la console:

Quand j’exécutais le script voilà ce que j’avais :
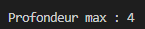
Et effectivement la profondeur maximum de mon dossier « test » était de 4 :
Mais le fichier «fichierConcat.md» ressemblait à ça :
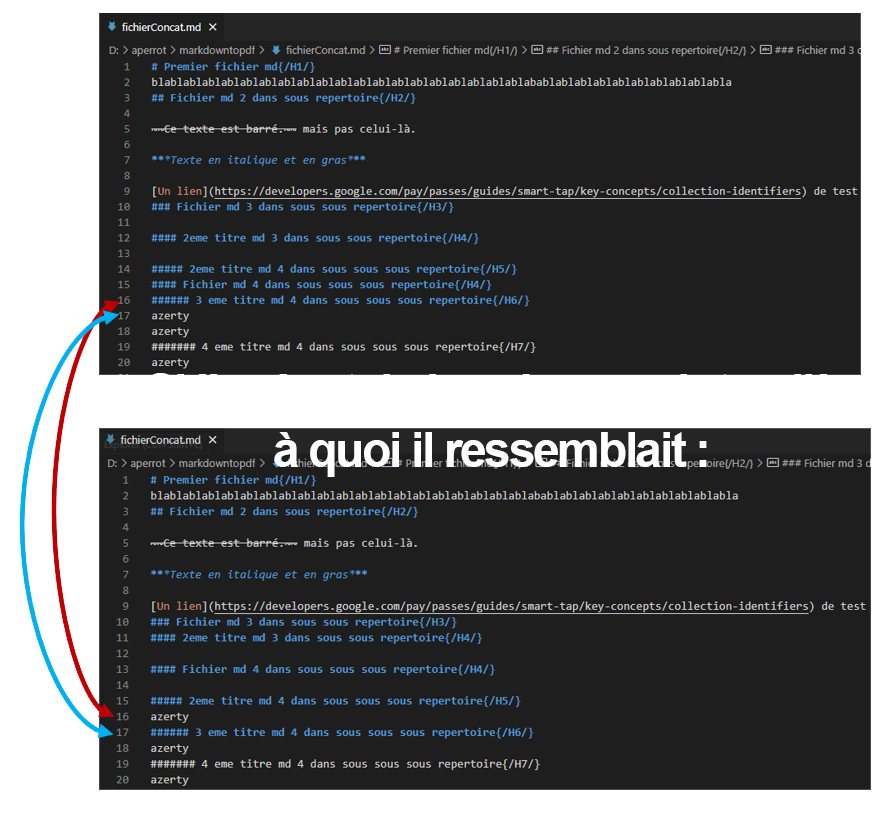
Comme on le voit certaines lignes changent de places.
J’ai mis du temps à comprendre d’où venait le problème, il vient de la fonction appendFile() qui est à la base Asynchrone.
En même temps j’en ai profité pour faire en sorte que les fichiers _index.md soient avec une profondeur de moins comme me l’avait demandé Johann Dantant.
Pour résoudre le problème d’appendFile() je devais trouver le moyen de le passer en Synchrone.
Il suffisait seulement d’ajouter « Sync » :

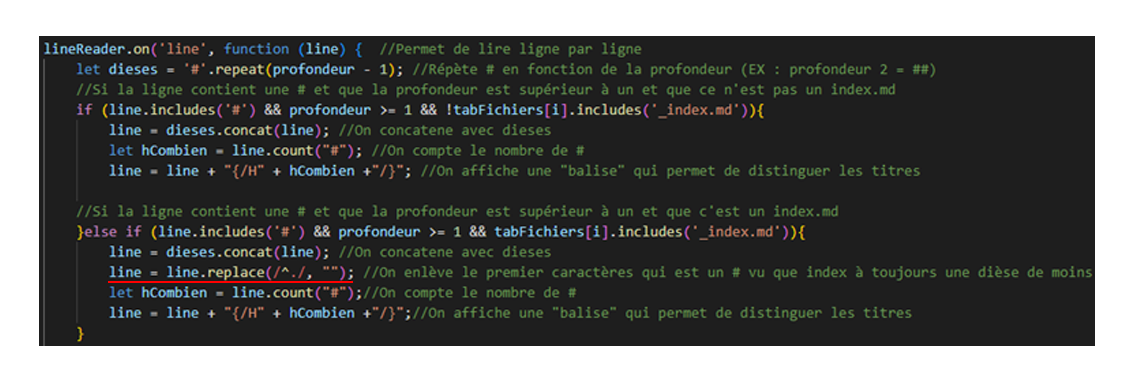
Pour ce qui est des fichiers index.md qui devaient avoir une profondeur de moins j’ai simplement supprimé un « # » :
Une fois opérationnel j’ai voulu exécuter mon programme sur l’arborescence « SpringCore » que Johann m’avait fourni.
Cependant ça prenait plus de 2 minutes. J’ai donc cherché d’où pouvait venir le problème et il venait du module natif de NodeJs : fs.
J’ai donc cherché si une bibliothèque existait et effectivement : graceful-fs faisait exactement le même travail mais était apriori bien plus optimisé :
La création du fichier «fichierConcat.md» prenait maintenant moins de 6 secondes.La profondeur maximum dans l’arborescence était de 7.
À partir de 7 ‘#’ les titres sont affichés en brut. Si un titre avec trois dièses est en profondeur 7
il deviendra donc un titre avec 10 dièses ce qui pose un problème. Johann Dantant m’a donc demandé de créer un petit script pour répertorier
tous les titres supérieurs à 6 et lui envoyer pour qu’il me donne les prochaines directives à suivre.
Voici un exemple de ce qui devrait-être corrigé :
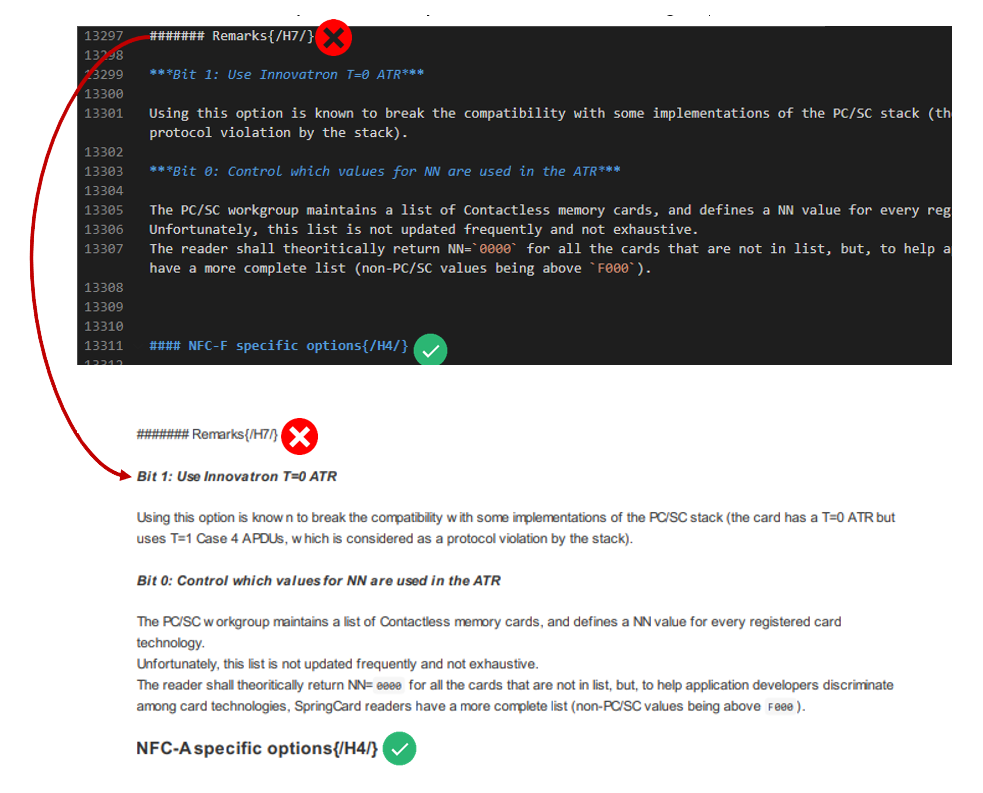
On voit bien que tout s’affiche correctement, les « balises »
qui permettent de distinguer les titres fonctionnent cependant les « # » s’affichent en brut à partir de 7. Une fois mon script créé voilà ce qu’il m’affichait :

Le fichier faisait plus de 350 lignes et une ligne sur deux représentait le titre à corrigé avec son emplacement dans l’arborescence comme me l’avait demandé Johann Dantant :

Johann Dantant seulement pouvait corriger les titres dépassant les 6 dièses puisqu’il voulait les corriger mais également les replacer dans l’arborescence.
J’ai donc voulu me mettre à la présentation du fichier final PDF mais avant cela je voulais m’assurer que le fichier PDF était correct.
Les éléments des premières pages étaient bien placés cependant après quelques pages j’ai remarqué que des éléments étaient mal placé puis
j’ai regardé la dernière page qui ressemblait à ça :
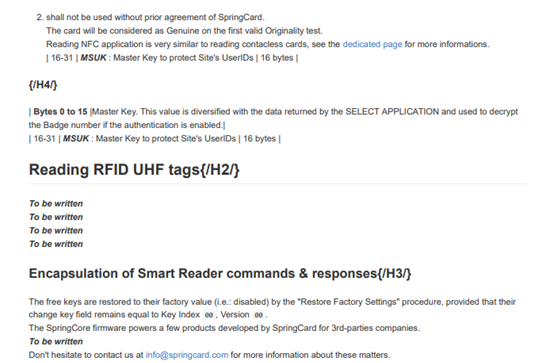
J’ai compris qu’il était encore une fois histoire d’Asynchrone puisque la ligne n’était pas au bon endroit et voilà ou elle était dans l’arborescence :
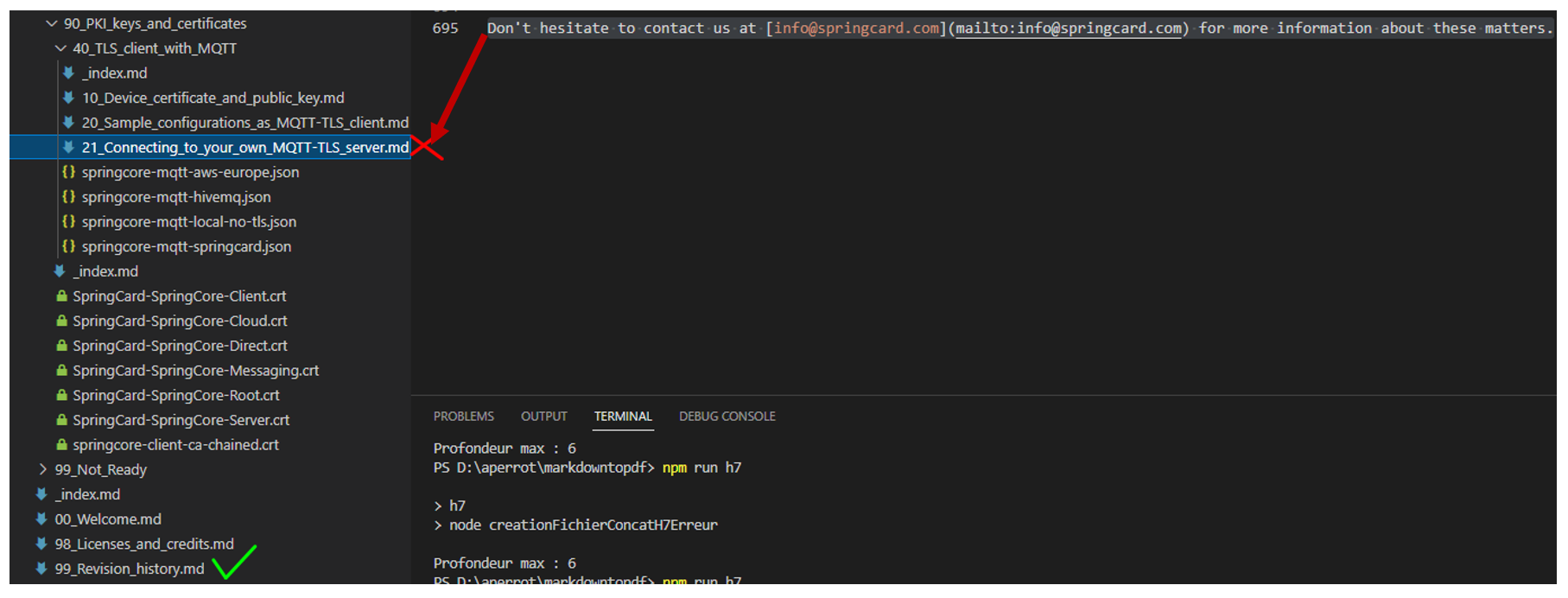
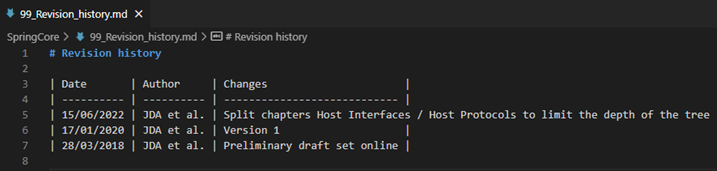
Le dernier fichier qui devait être traité est 99_revision_history et il se termine avec ce tableau :
J’ai donc effectué des recherches et il s’avère que le module natif NodeJS « Readline » est également Asynchrone.
J’ai trouvé une bibliothèque du nom de Readline-sync mais le problème c’est que ça prenait en compte seulement la saisie des utilisateurs.
Il n’y avait donc aucun moyen déjà créé pour lire mes fichiers en Synchrone et donc dans l’ordre.
J’ai donc appris de nouvelles notions pour forcer le Synchrone en réalisant des tests dans un premier temps :
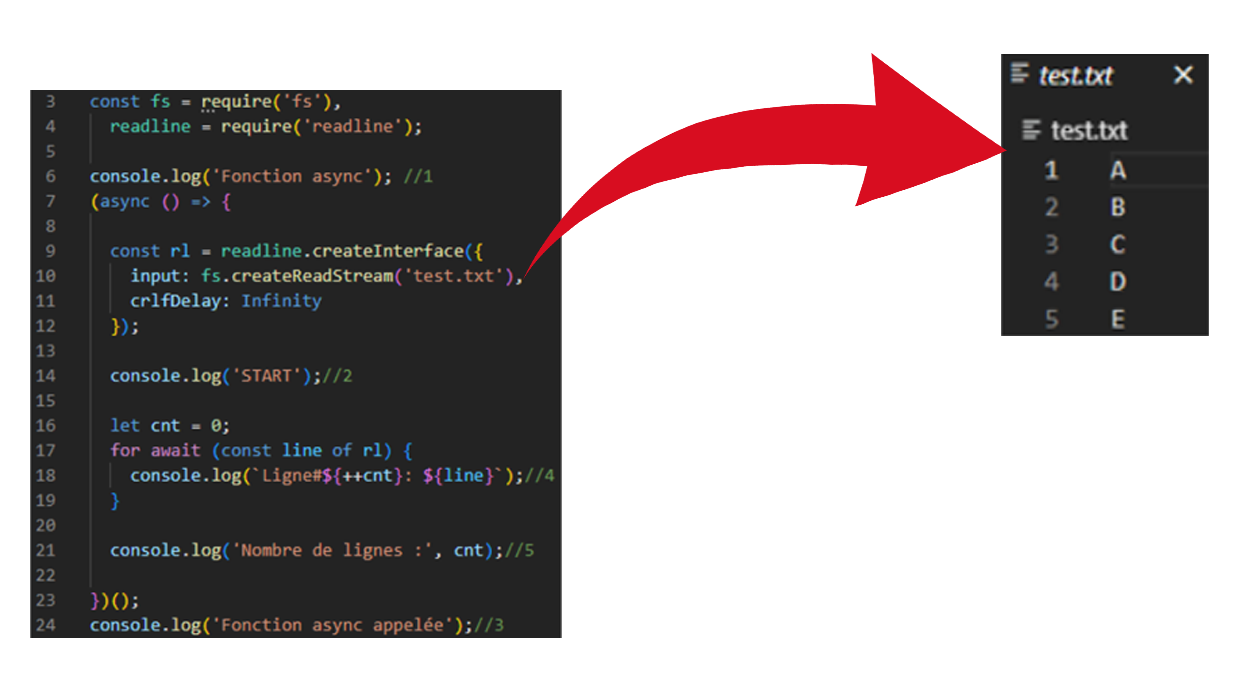
Et voici le résultat obtenu :
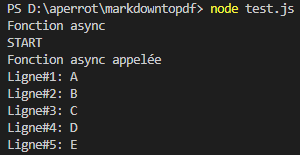
J’avais donc appris plusieurs notions :
L'opérateur await permet d'attendre la résolution d'une promesse (Promise : Une promesse représente une valeur qui peut être disponible maintenant,
dans le futur voire jamais.). « await » ne peut être utilisé qu'au sein d'une fonction asynchrone (définie avec l'instruction async() ).
Cependant ces notions restaient assez floues et j’ai essayé d’intégrer mon test.js à mon fichier « creationFichierConcat.js »
pour réaliser les opérations dans l’ordre et donc avoir les lignes dans le bon ordre mais ça ne fonctionnait pas.
J’ai cherché une autre alternative et je me suis souvenu que quand je lisais l’entièreté d’un fichier avec la fonction readFileSync()
j’obtenais le contenu dans l’ordre mais il n’était pas lu ligne par ligne. J’ai remarqué que ce qui séparait deux lignes c’était le retour
à la ligne (« \n\r » en programmation). J’ai donc cherché un moyen de lire mes fichiers avec readFileSync() et de séparer les lignes pour
les mettre dans un tableau puis les lire une par une. J’ai trouvé la fonction split() :
C’est une fonction de chaîne de caractères qui est utilisée pour diviser la chaîne en sous-chaînes. Cette fonction renvoie la sortie sous forme de tableau.
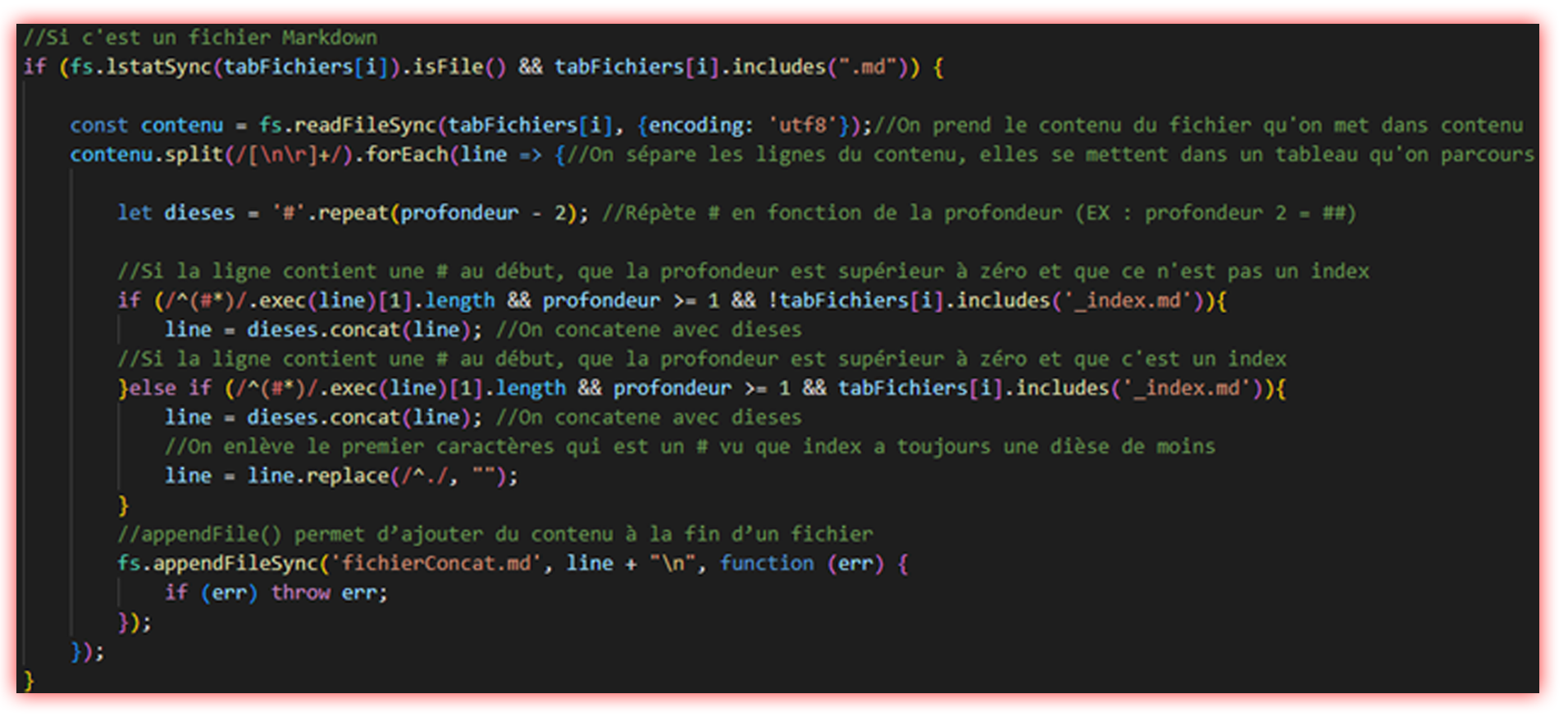
En plus de cela j’ai remarqué que dans mes conditions je regardais uniquement si la ligne avait un # mais il faut que ce dièse soit au début.
J’ai donc procédé comme ceci et ça fonctionnait enfin :
Mission 7 : Feuille de style du PDF avec la Charte Graphique
Comme je l’ai dit précédemment la bibliothèque MDPDF prend en charge les feuilles de style en cascade (CSS).
Cela veut dire qu’il est facile d’ajouter des polices d’écritures, des couleurs etc… à des documents Web comme le HTML.

La Charte Graphique m’a ensuite été transmise et en voici une partie :

Pour transformer mon fichier Markdown en PDF je devais faire :
Mais maintenant que je veux ajouter une feuille de style, un haut de page et un bas de page personnalisé je dois configurer les options de la bibliothèque MDPF :
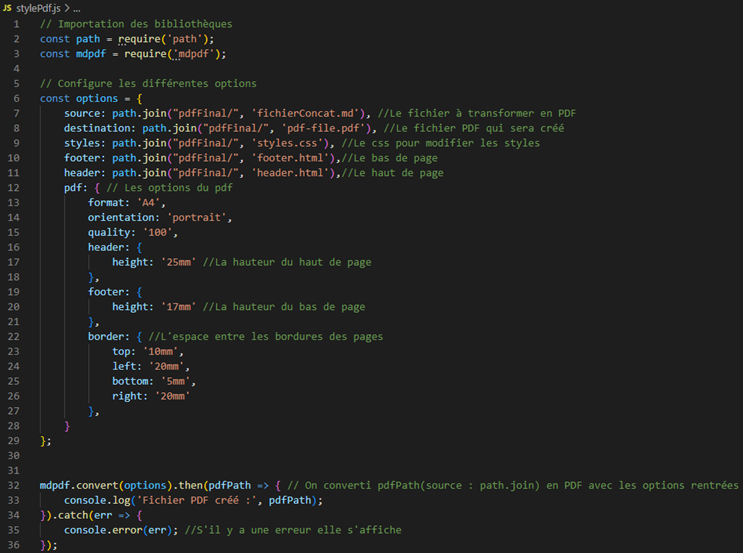
Les options et l’utilisation de celles-ci sont expliquées sur la page de la bibliothèque.
Dans les options j’appelle en premier la source qui est le fichier qui contient toute mon arborescence puis je saisie sa destination et son nom.
Ensuite j’utilise la feuille de style, le pied de page et l’en-tête.
J’ai adapté la feuille de style à la Charte Graphique puisque Johann Dantant voulait avoir le niveau des titres jusqu’à 6 et
faire en sorte que si ça dépasse 6 ce soit avec un fond jaune fluo :
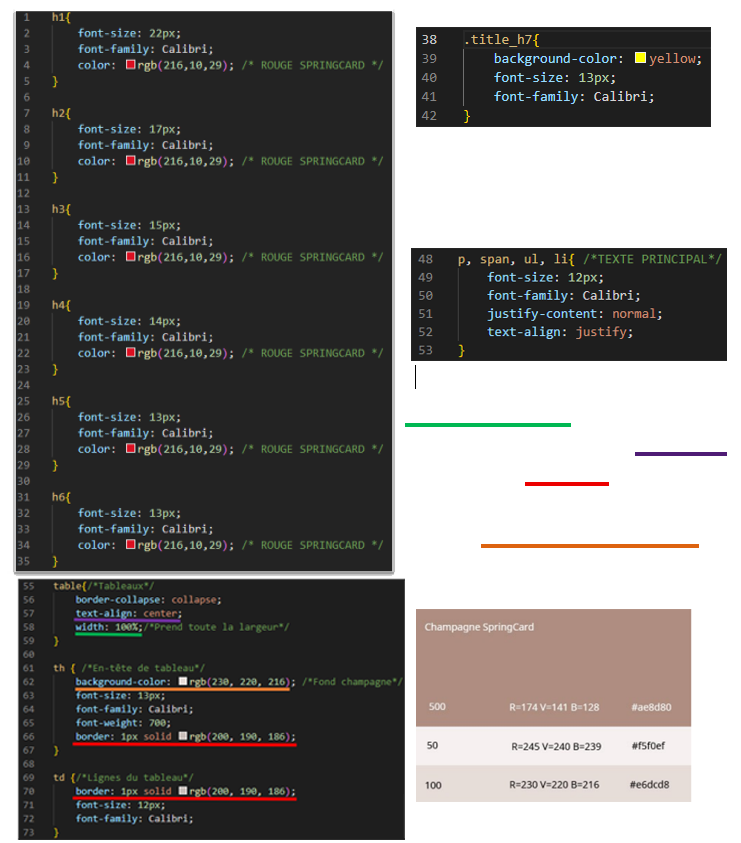
Pour afficher un fond jaune fluo j’ai compté le nombre de # et si ça dépassait 6 alors je changeais le style du titre en ‘.title_h7’ :

Voilà à quoi ressemblait une page comportant des titres, des tableaux et un titre qui dépassait 6 ‘#’:

Pour l’en-tête j’ai affiché le logo SpringCard, voici le css de l’en-tête :
Et le HTML qui utilise le CSS avec les ‘class’ précédemment créées.

J’obtenais le résultat attendu :
Pour ce qui est du pied de page j’ai tenté de reproduire celui de la charte graphique :

Avec une barre qui sépare en haut, un texte et en bas à droite le numéro des pages.
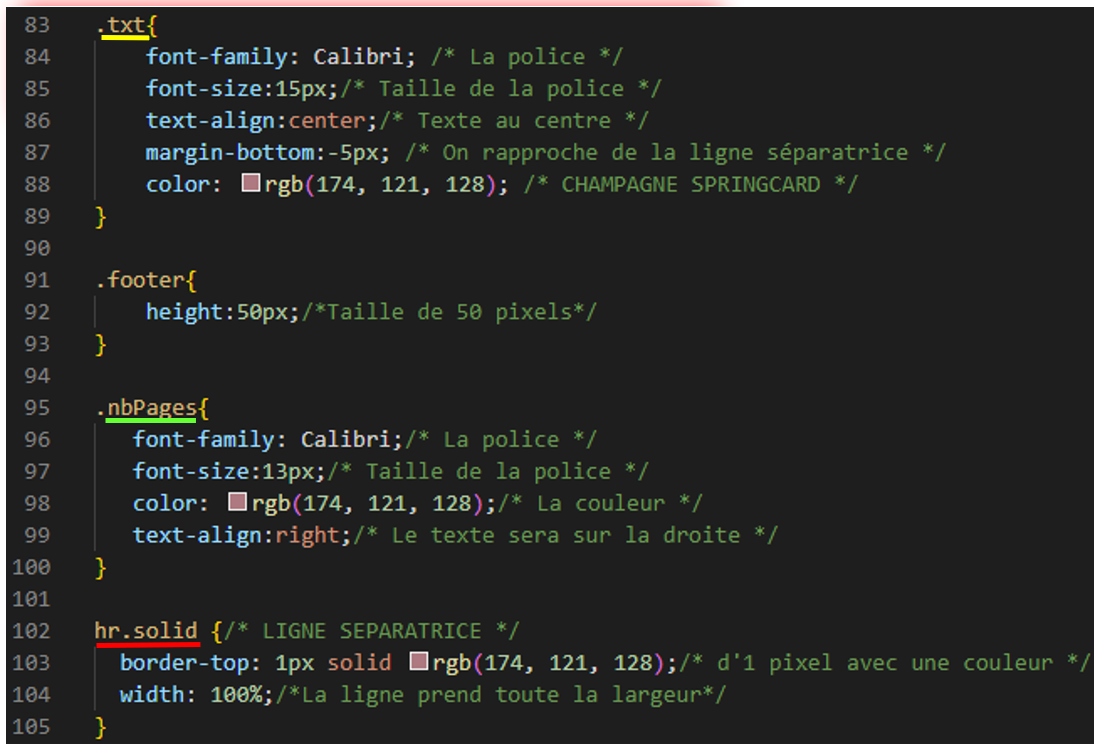
Et le HTML qui utilise le CSS avec les ‘class’ précédemment créées :

Pour ce qui est des class ‘pageNumber’ et ‘totalPages’ elles sont fournies par la bibliothèque mdpdf qui utilise elle-même une bibliothèque du nom de puppeteer.
Ces class devaient me permettre d’afficher automatiquement la page actuelle et le nombre de pages au total.
La bibliothèque mdpdf utilisait la version 2 de puppeteer et voilà à quoi ressemblait le pied de page :

Comme vous pouvez le constater mon pied de page s’affiche bien mais les numéros de pages ne s’affichent pas.
J’ai donc contacté le créateur de la bibliothèque mdpdf. Celui-ci m’a expliqué qu’effectivement j’utilisais la bibliothèque correctement
mais la version actuelle de puppeteer était la 15 et sa bibliothèque utilisait la version 2.
Il a donc, à la suite de ma demande mis à jour sa bibliothèque et voilà à quoi ressemblait mon pied de page :

Le problème était donc la compatibilité entre les deux bibliothèques mdpdf et puppeteer ce qui m’a empêché d’afficher correctement les numéros de pages. Je travaille actuellement avec le créateur de mdpdf pour tenter de remettre totalement à jour sa bibliothèque. J’ai donc créé deux méthodes différentes pour Johann DANTANT en attendant. Il peut choisir entre :
- Les numéros de pages s'affichent mais mal puisque la dernière version de Puppeteer utilisée par la bibliothèque MDPDF ne prend pas en compte le header / footer.
- Les numéros de pages ne s’affichent pas mais le footer et le header eux fonctionnent bien.
- Les numéros de pages s'affichent mais mal puisque la dernière version de Puppeteer utilisée par la bibliothèque MDPDF ne prend pas en compte le header / footer.
- Les numéros de pages ne s’affichent pas mais le footer et le header eux fonctionnent bien.